Case Study
Charivo
Modular Live2D + LLM framework for building interactive AI characters with pluggable voice and rendering layers.
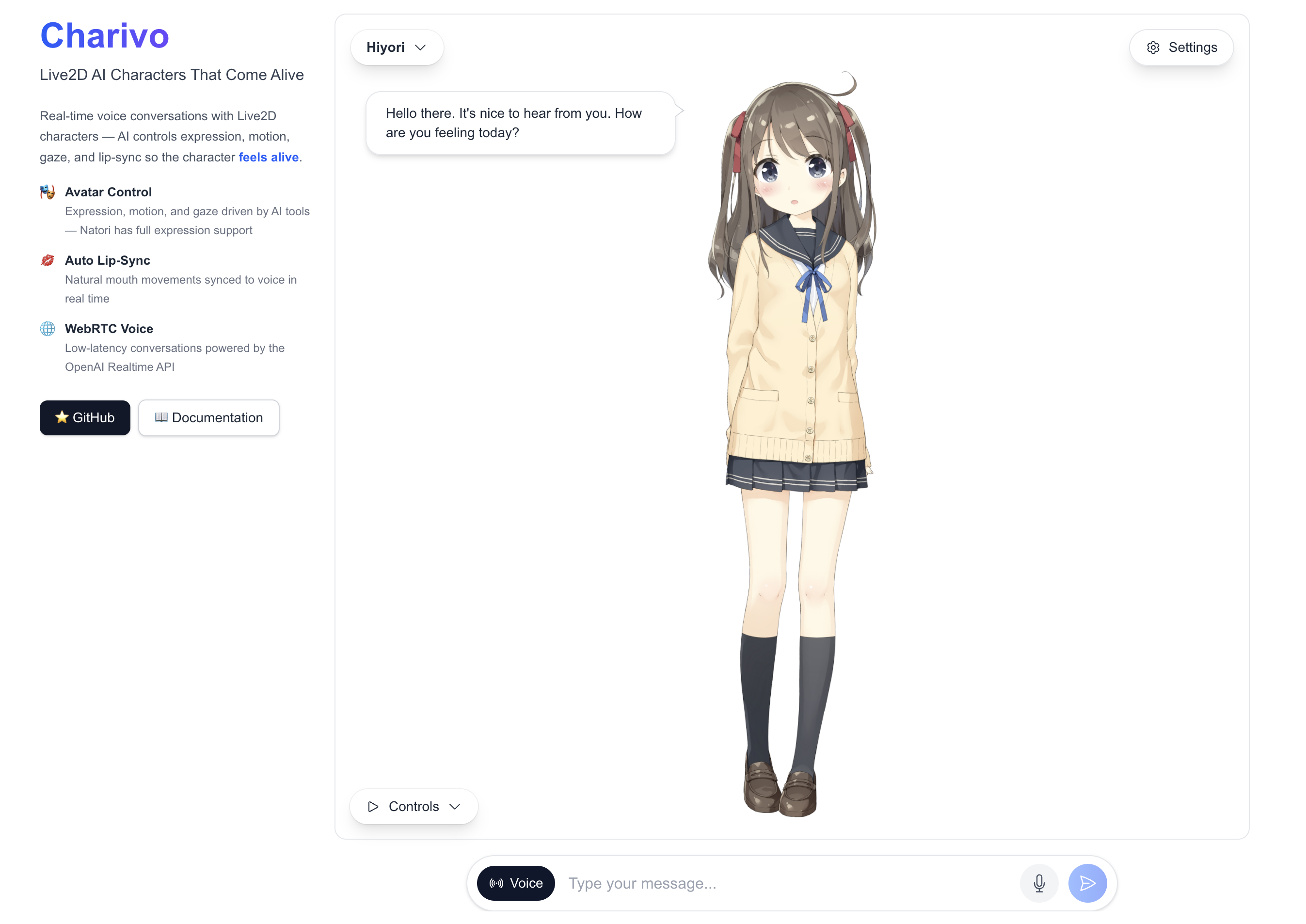
Charivo splits an interactive AI character into parts that come apart. Rendering (Live2D), language (the LLM), and voice (TTS/STT) live in separate packages wired together through interfaces — so swapping the TTS provider, or dropping in a different model, never means touching the renderer.
How it’s put together
The framework keeps four concerns apart: orchestration, stateful managers, browser-side clients, and server-side providers. You compose a character from independent packages:
@charivo/core— the orchestrator: attach a renderer, an LLM, and a TTS player, then callcharivo.userSay("...")@charivo/render+@charivo/render-live2d— Live2D model loading, motion playback, and mouse/gaze tracking@charivo/llmand@charivo/tts— a manager + client split, with/remoteclients that keep provider keys on the server instead of in the browser@charivo/realtime— swap the LLM + TTS pair for a single speech-to-speech manager
Keeping browser clients and server providers on opposite sides of that line is deliberate: the frontend never holds a provider credential.
Realtime voice
For low-latency conversation you attach a realtime manager instead of the LLM + TTS pair. The browser streams microphone audio to a server route and plays the model’s voice straight back — and because one character session drives the renderer too, a reply moves the character’s expression and motion, not just its mouth.
Two live demos: the Live2D web app and the Companion, which adds realtime voice with cross-session memory.